
NetFlix Director
NetFlix Director Chris Pouliot spoke on the topic: “Building a Data Science Team from scratch”. I think below was his first slide:

Fig: NetFlix so called “culture” slide.
Director was projecting NetFlix’s culture: “If you don’t have impact, you should be fired”. All throughout the conference, I was taking photographs of interesting slides through my iPad. However for NetFlix I didn’t have anything else other than the one you see above. It seems like NetFlix presentation didn’t have any impact on me, so NetFlix you are fired from my article. Good luck with your great culture. World has seen several times how long these sort of culture has lasted.
IBM – Distinguished Engineer
IBM’s distinguished engineer Stephen Brodsky spoke on the subject: “Big Data, Analytics and Watson”. Couple of things stood out in his presentation:
- Word “Zetabyte”
- Big Data Eco system.
Several years back, I was only aware of Gigabyte. Few years back I learnt about Terabyte. Couple of year’s back I learnt about Petabyte. Recently in this conference IBM speaker used the phrase Zetabyte which is 1000,000,000,000,000,000,000 bytes. It’s incredibly fascinating & unbelievable to see such monesterous numbers.
Just to make sure I am head of curve (at least in learning memory size), I learnt what’s ahead of Zetabyte from wikipedia, which is:
|
Value |
||||
| 1000 | kB | kilobyte | ||
| 10002 | MB | megabyte | ||
| 10003 | GB | gigabyte | ||
| 10004 | TB | terabyte | ||
| 10005 | PB | petabyte | ||
| 10006 | EB | exabyte | ||
| 10007 | ZB | zettabyte | ||
| 10008 | YB | yottabyte | ||
| It might be appropriate to share an interesting quote from Bill Gates which he made on 1997: “640K is enough for anyone”. | ||||
Then IBM put-forth following slide showing essential open source components of Big Data. If you are interested to become a big data expert, here are must to learn technologies.

Fig: Big Data ecosystem
Google Director of Engineering
Google’s Director of Engineering Dan Strutsman started his speech by showing their data centers photographs. It was really cool. He told that but for cement concrete in their data center, everything else is built by them for high efficiency. One of my wish is to see and experience such massive datacenters in person.

Fig: Google Data Center inside

Fig: Google Data Center outside

Fig: Showing their private network cables that runs under the ocean
Few slides later Director disclosed their big data architecture, citing that this is their architectural pattern for any major initiative in google.
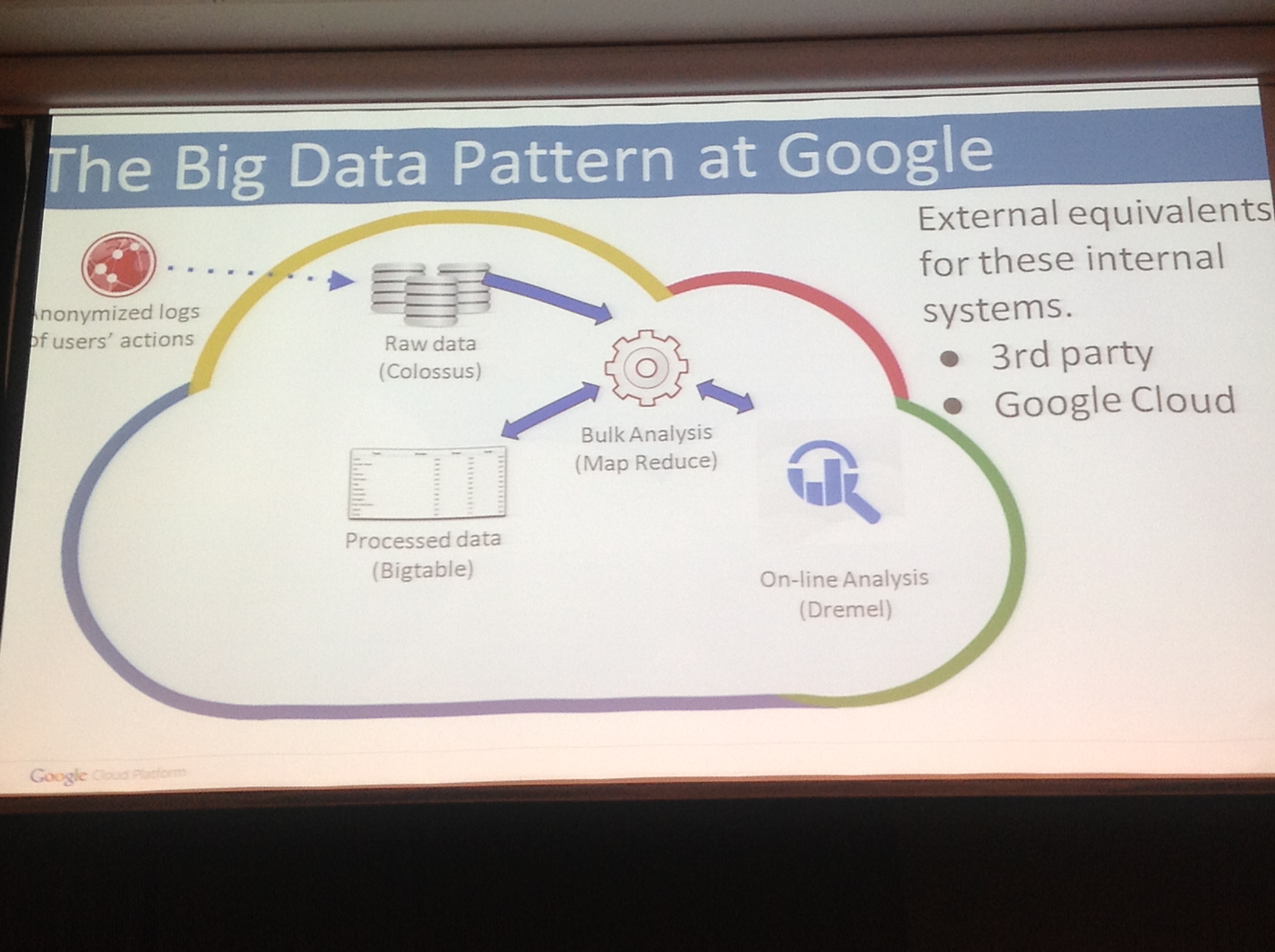
Fig: Standard architectural pattern in google
- Logs from users or raw data are stored in Colossus. Colossus is a massive storage medium – which today is used in several of their services like: Search Indexing, Gmail, Google Docs, Youtube….
- Map Reduce algorithm (actual product is MapR) is used to crunch the data at an unimaginable rate and stores the processed data in their BigTable.
- Big Table is a distributed storage for managing structured data that is designed to scale to a very large size.
- Then Dremel is used to get the data from the Big Table. Dermel is basically query language (just like SQL), which is capable of running aggregation queries over trillion-row tables in seconds.
These numbers are just beyond imagination. There is a famous saying that: “If technology goes beyond a point, it would become like a magic”. Indeed these are google magic. Google has published white papers on all these technologies, those are the hyperlinks that you see in the previous points.
Then director presented the slide on Google’s technology innovation. They have been consistently producing superior quality, beyond imagination technology products every 2 years:
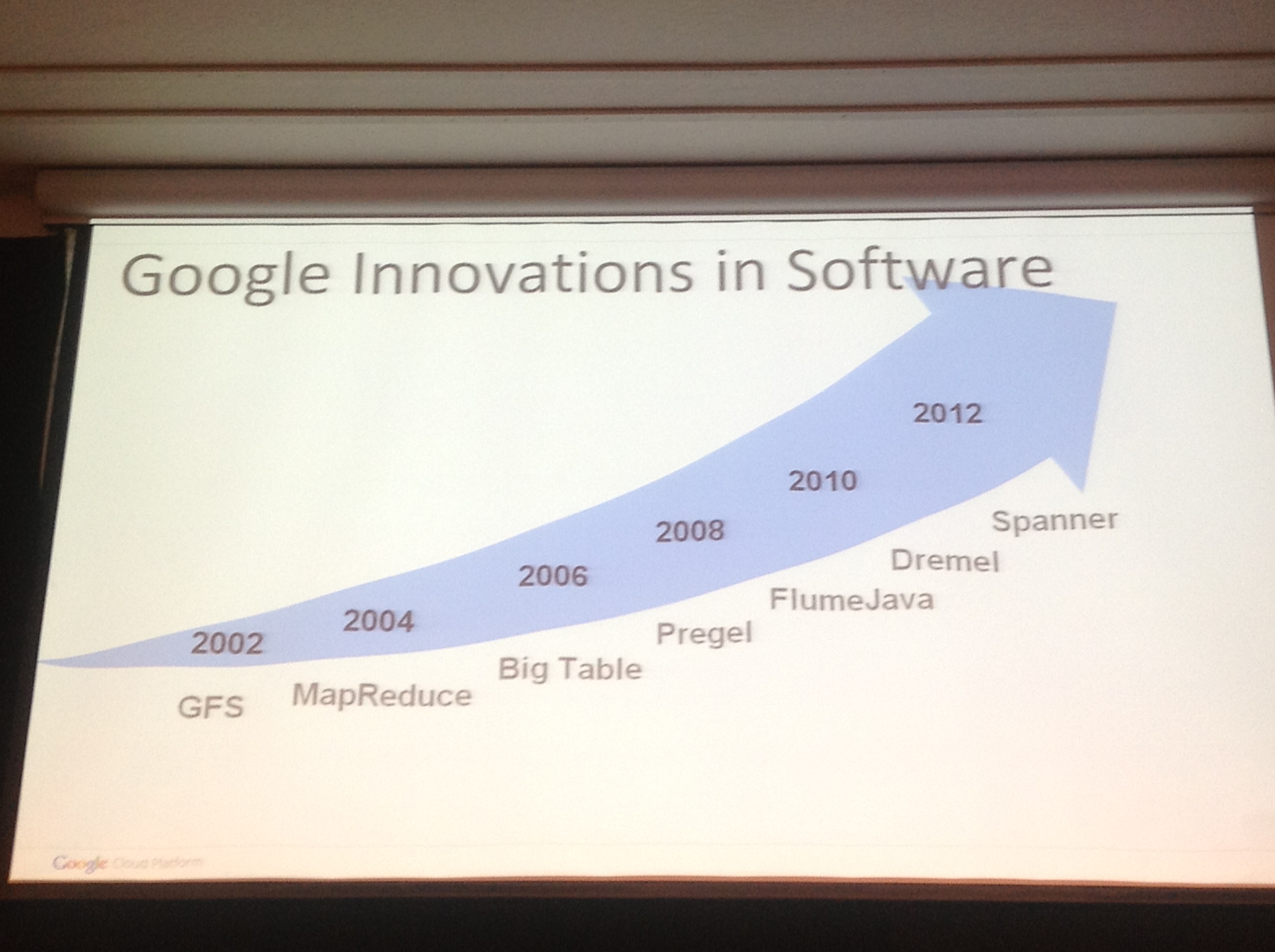
Fig: Showing Google innovations in technology
Conclusion
I have attended several technical conferences, but IEEE was quite a remarkable and beyond comparison with prior conferences. Indeed it gave me a gratifying and big (data) experience.

Leave a comment