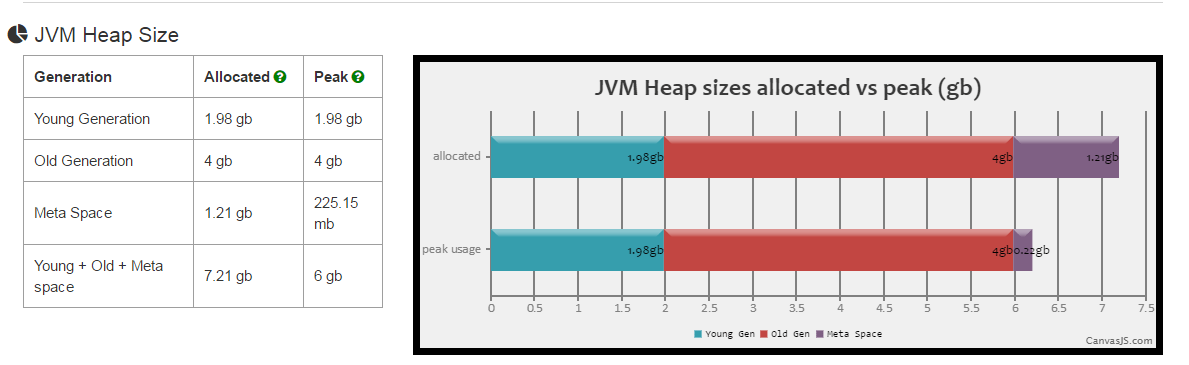
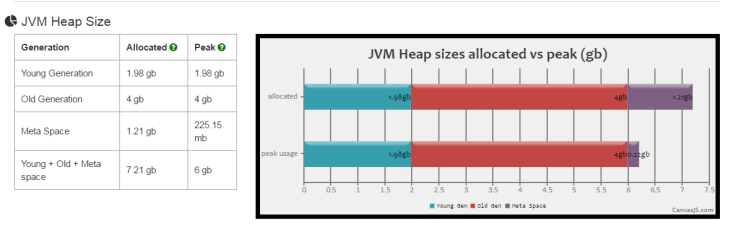
Fig: Java Heap sizes generated from http://gceasy.io
What are different regions in JVM memory?
There are 5 regions.
- Eden
- Survivor 1
- Survivor 2
- Old (or Tenured) Generation
- Perm Generation (until Java 7). From Java 8 Perm Generation has been replaced with Metaspace.
Note: Eden, Survivor 1 and Survivor 2 are collectively called as Young Generation.
Can you explain the purpose of each region in Java Memory?
Eden Generation: When an object is newly constructed it’s created in Young Generation. In most of the applicationsm most of the objects are short-lived objects. i.e. they will die soon. Thus they will get garbage collected within the Young Generation itself
Survivor: Objects that survive Minor GC are not directly promoted to the Old Generation. They are kept in the Survivor region for certain number of Minor GC collections. Only if they survive certain number of Minor GC collections then they are promoted to Old Generation.
Old (or Tenured) Generation: Certain objects tend to be long lived. Example: Application Context, HTTP Sessions, Caches, Connection Pools, …… Those long lived objects are promoted to old generation.
Perm Generation: This is the location where JVM objects such as Classes, Methods, String Interns…. are created.
Metaspace: Starting from Java 8 Perm generation has been replaced with Metaspace for performance reasons.
What are the different types of GCs?
There are 3 types of GCs:
- Minor GC
- Major GC
- Full GC
Minor GC: It’s also called as Scavenge GC. This is the GC which collects garbage from the Young Generation.
Major GC: This GC collects garbage from the Old Generation
Full GC: This GC collects garbage from all regions i.e. Young, Old, Perm, Metaspace.
When Major or Full GC run all application threads are paused. It’s called as stop-the-world events. In Minor GCs also stop-the-world event occurs but momentarily.
What are different types of GC algorithms?
- Serial
- Parallel
- CMS
- G1
Serial: The serial collector uses a single thread to perform all garbage collection work. It is best-suited to single processor machines, because it cannot take advantage of multiprocessor hardware. It’s enabled with the option -XX:+UseSerialGC.
Parallel: The parallel collector (also known as the throughput collector) performs minor collections in parallel, which can significantly reduce garbage collection overhead. It is intended for applications with medium-sized to large-sized data sets that are run on multiprocessor or multithreaded hardware. It’s enabled with the option -XX:+UseParallelGC.
CMS: The mostly concurrent collector performs most of its work concurrently (for example, while the application is still running) to keep garbage collection pauses short. It is designed for applications with medium-sized to large-sized data sets in which response time is more important than overall throughput because the techniques used to minimize pauses can reduce application performance. It’s enabled with the option -XX:+UseConcMarkSweepGC
G1: G1 is the latest garbage collector, targeted for multi-processor machines with large memories. It meets garbage collection (GC) pause time goals with high probability, while achieving high throughput. Whole-heap operations, such as global marking, are performed concurrently with the application threads. It’s enabled with the option -XX:+UseG1GC
What are the merits and demerits of each GC algorithm?
To see the Pros and Cons of each algorithm refer – https://blog.tier1app.com/2015/04/19/which-gc-to-use/
What tools are used for analyzing Garbage Collection logs?
- http://gceasy.io
- IBM Pattern Modeling and Analysis Tool for Java Garbage Collector
- Oracle’s Visual GC, Java Mission Control

Leave a comment