
Even unpredictable weather is being forecasted. But after all these technological advancements, are we able to forecast our application performance & availability? Are we able forecast even for the next 20 minutes? Will you be able to say that in the next 20 minutes application is going to experience OutOfMemoryError, CPU spikes, crashes? Most likely not. It’s because we focus only on macro-metrics:
- Memory utilization
- Response time
- CPU utilization
These are great metrics, but they can’t act as lead indicators to forecast performance/availability characteristics of your application. Now let’s discuss few micrometrics that can forecast your application’s performance/availability characteristics.
EXAMPLE: 1
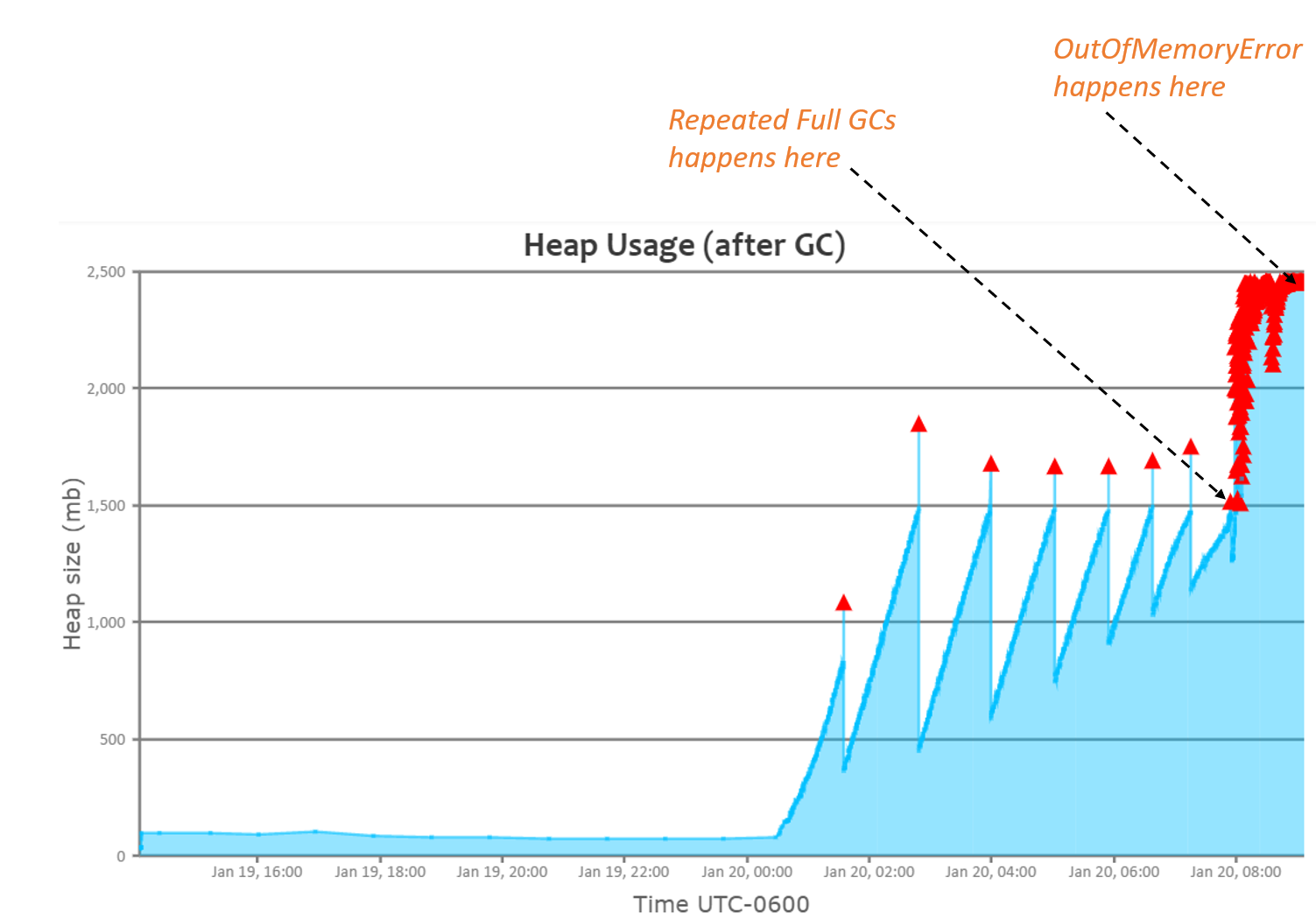
Fig: You can notice repeated full GCs triggered (graph from GCeasy.io)
Let’s start this discussion with an example. This application experienced OutOfMemoryError. Look at the heap usage graph (generated by parsing garbage collection logs). You can notice heap usage going higher & higher despite full GCs running repeatedly. This application experienced OutOfMemoryError around 10:00am, whereas repeated full GCs started happening right around 08:00am. Starting from 08:00am till 10:00am application was only doing repeated full GCs. If DevOps team would have monitored Garbage collection activity, they should have been able to forecast that application is going to experience OutOfMemoryError even a couple of hours before.
Memory related micrometrics
There are 4 memory/garbage collection related micrometrics that you can monitor:
- Garbage collection Throughput
- Garbage collection Pause time
- Object creation rate
- Peak heap size
Let’s discuss them in this section.
# 1. GARBAGE COLLECTION THROUGHPUT
Garbage Collection throughout is the amount of time application spends in processing customer transactions vs amount of time application spends in doing garbage collection.
Let’s say your application has been running for 60 minutes. In this 60 minutes, 2 minutes is spent on GC activities.
It means application has spent 3.33% on GC activities (i.e. (2 / 60) * 100).
It means Garbage Collection throughput is 96.67% (i.e. 100 – 3.33).
When there is a degradation in the GC throughput, it’s an indication of some sort of memory problem is brewing in the application.
# 2. GARBAGE COLLECTION LATENCY
When certain phases of Garbage Collection event run, entire application pauses. This pause is what referred as latency. Some Garbage collection events might take a few milliseconds, whereas some garbage collection events can take several seconds to minutes. You need to monitor GC pause times. If GC pause times starts to go higher, it will impact user’s experience.
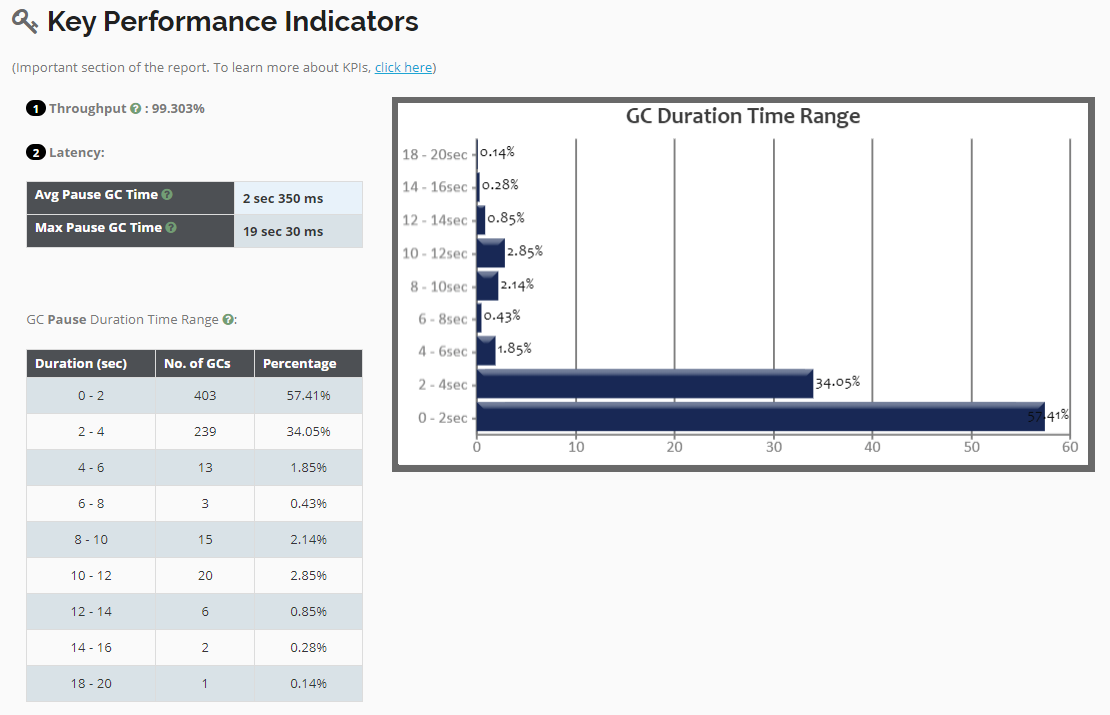
Fig:GC Throughput & GC Latency micrometric
# 3. OBJECT CREATION RATE
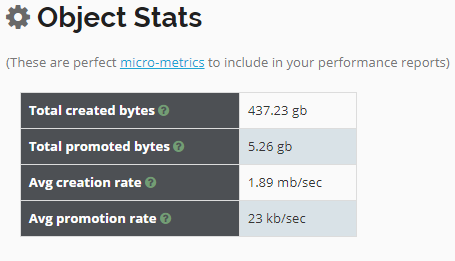
Fig: Object creation rate micrometric
Object creation rate is the average amount of objects created by your application. Say suppose your application was 100mb/sec. And recently it starts to create 150mb/sec without any increase in the traffic volume – then it’s an indication of some problem brewing in the application. This additional object creation rate has potential to trigger more GC activity, increase CPU consumption & degrade response time.
You can use this same metric in your CI/CD pipeline as well to measure the quality of code commit. Say in your previous code commit your application was creating 50mb/sec. Starting from recent code commit, say your application starts to create 75mb/sec for the same of amount traffic volume – then it’s an indication of some inefficient code commit to your repository.
# 4. PEAK HEAP SIZE
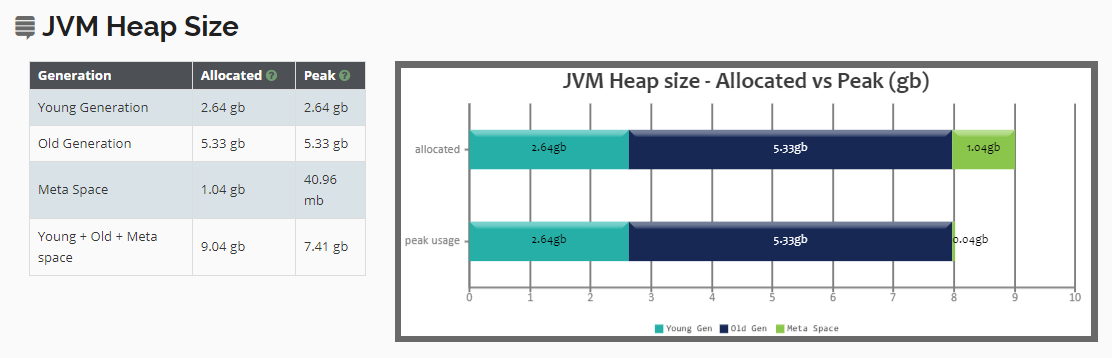
Fig: Peak Heap size micrometric
Peak heap size is the maximum amount of memory consumed by your application. If peak heap size goes beyond a limit you must investigate it. Maybe there is a potential memory leak in the application, newly introduced code (or 3rd libraries/frameworks) is consuming lot of memory.
How to generate memory related micrometrics?
All the memory related micrometrics can be sourced from garbage collection logs.
(1). You can enable the garbage collection logs by passing following JVM arguments:
Till Java 8:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<file-path>
From Java 9:
-Xlog:gc*:file=<file-path>
(2). Once garbage collection logs are generated you can either manually the GC logs to GC log analysis tools such as GCeasy.io or using programmatic REST API. REST API is useful when you want to automate the report generation process. It can be used in CI/CD pipeline as well.
EXAMPLE 2
After few hours of launch a major financial application started to experience ‘OutOfMemoryError: unable to create new native thread’. This application turned ON a new feature in their JDBC (Java Database Connectivity) driver. Apparently, this feature had a bug, due to which JDBC driver started to spawn new threads repeatedly (instead of re-using same threads). Thus, within a short duration of time, application started to experience ‘OutOfMemoryError: unable to create new native thread’. If team would have monitored thread count and thread states, they could have caught the problem quite early on and prevented the outage. Here are the actual thread dumps captured from the application. You can notice that RUNNABLE state thread count growing between each thread dump over period.

Fig: Growing RUNNABLE state Thread count (graph from fastThread.io)
Thread related micrometrics
There are 4 thread related micrometrics that you can monitor:
- Thread Count
- Thread States
- Thread Groups
- Thread Execution patterns
Let’s discuss them in this section.
# 5. THREAD COUNT
Thread count is an interesting metric to monitor. If thread count goes beyond a limit it can cause CPU, memory problems & application crashes. Too many threads can cause ‘java.lang.OutOfMemoryError: unable to create new native thread’. Thus, if thread count keeps peeking up in the application it can be an indication of some sort of brewing problem in the application.
#6. THREAD STATES
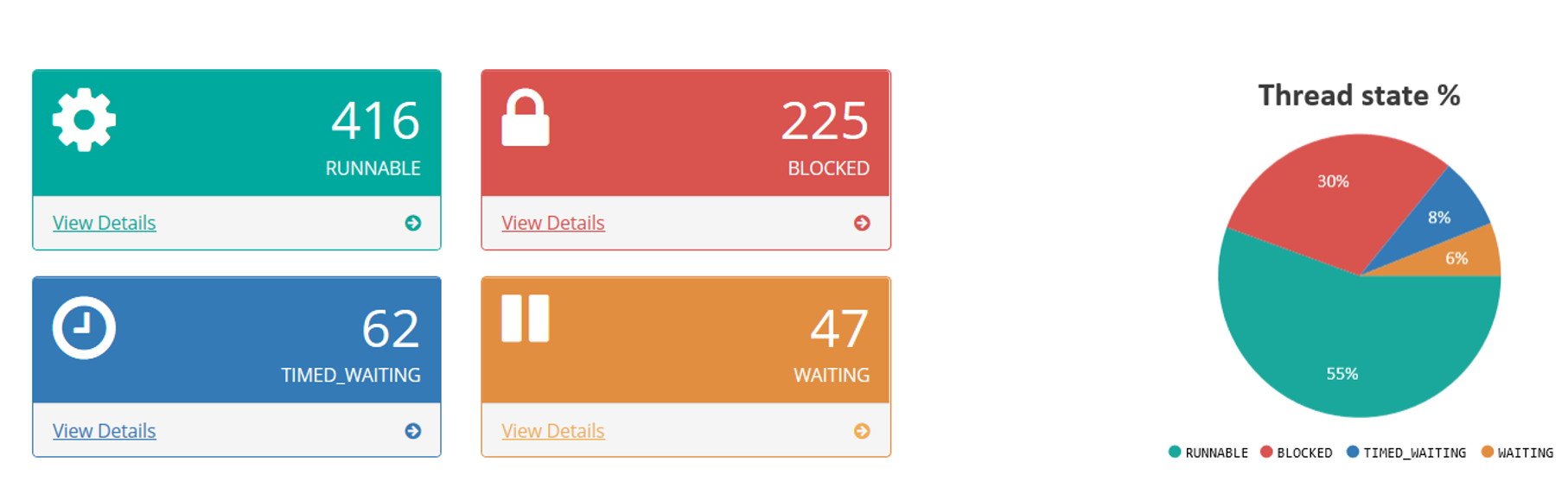
Fig: Thread states micrometric
Application threads can be in different 6 different states: NEW, RUNNABLE, WAITING, TIMED_WAITING, BLOCKED, TERMINATED. Too many threads in RUNNABLE state can cause CPU spike. Too many threads in BLOCKED state can make application unresponsive. If number of threads in a particular thread state exceeds your application’s typical threshold then it’s an early indicator of performance hazard building up in your application.
# 7. THREAD GROUPS
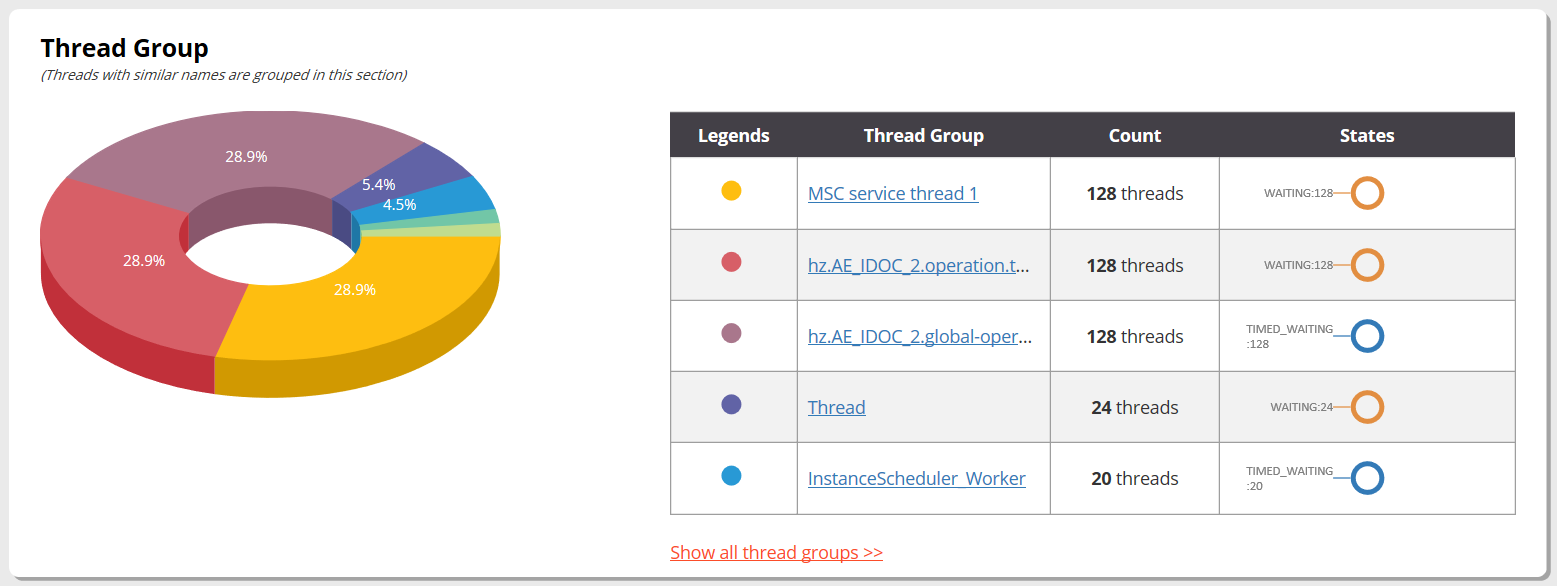
Fig: Thread Group micrometric
A thread group is a collection of threads that perform similar tasks. There could be a servlet container thread group that processes all the incoming HTTP requests. There could be a JMS thread group, which handles all the JMS sending, receiving activity. There could be some other sensitive thread groups in the application as well. You monitor those thread groups size. You don’t want their size neither to drop below a threshold nor go beyond a threshold. Less number of threads in a thread group can stall the activities. More number of threads can lead to memory, CPU problems.
# 8. THREAD EXECUTION PATTERNS
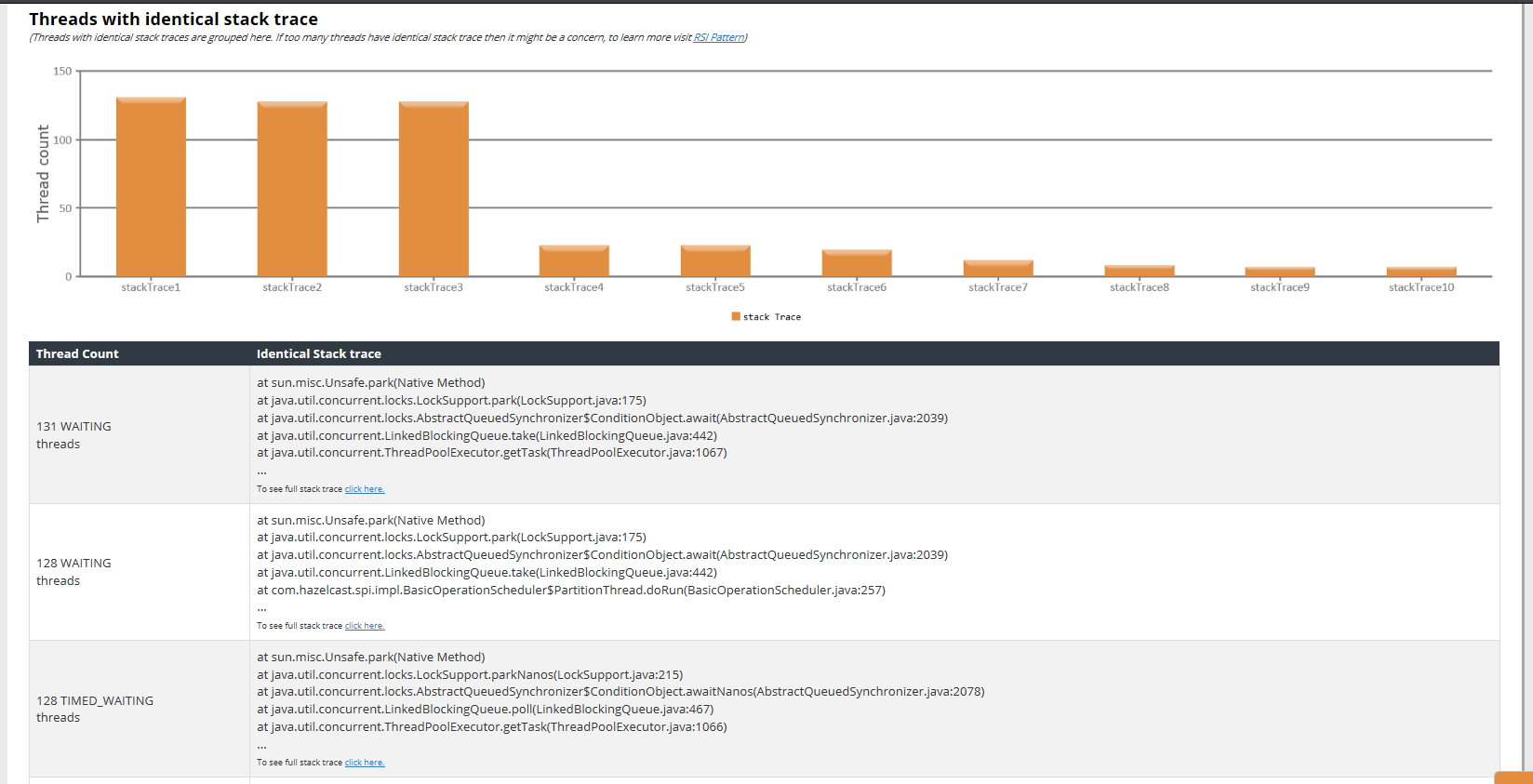
Fig: Threads with identical stacktrace
Whenever significant number of threads starts to exhibit identical/repetitive stack trace then it may be indicative of performance problems. Consider these scenarios:
(a). Say your SOR or external service is slowing down then a significant number of threads will start to wait for its response. In such circumstance, those threads will exhibit same stack trace.
(b). Say a thread acquired a lock & it never released then, then several other threads which are in the same execution path will get into the blocked state, exhibiting same stack trace.
(c). If a loop (for loop, while loop, do..while loop) condition doesn’t terminate then several threads which execute that loop will exhibit the same stack trace.
When any of the above scenarios occurs application’s performance, and availability will be jeopardized. You might want to focus on thread execution patterns.
How to generate thread related micrometrics?
All the thread related micrometrics can be sourced from thread dump:
- There are several options to capture thread dump from your application. You may choose the option that is convenient to you. It’s advisable to capture thread dumps in gap of 5 – 10 seconds to do analysis.
- Once thread dumps are generated you can either manually analyze them through thread dump analysis tools such as fastThread.io or using programmatic REST API. REST API is useful when you want to automate the report generation process. It can be used in CI/CD pipeline as well.
Network related micrometrics
There are 3 network related micrometrics that you can focus on:
- TCP/IP connection count by host
- TCP/IP states
- Open File descriptors
Let’s discuss them in this section.
# 9. TCP/IP CONNECTION COUNT BY HOST
Modern application connects with multiple external applications (Needless to say in microservices world, where there is too many external connectivity). Connections are established in various protocols: HTTP, HTTPS, SOAP, REST, JDBC, JMS, Kafka… In this kind of ecosystem your application’s responsiveness and availability is dependent on external applications availability and responsiveness as well. Thus, you need to monitor number of connections established from your application to external applications. If you see connection count to be growing more than normal traffic volume pattern, then it can be a concern. Whenever there is slow down in the external application, there is a possibility for your application to open more and more connections to the external application to handle the incoming transactions.
You can find number of established connections to external systems using the ‘netstat’ command, as shown below:
$ netstat -an | grep ESTABLISHED | grep '162.187.223.11' | wc -l
Above command will show number of established connections to the host ‘162.187.223.11’.
# 10. TCP/IP STATES
There are 11 different TCP/IP states: LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2, CLOSE-WAIT, CLOSING, LAST-ACK, TIME-WAIT, CLOSED. You need to monitor number of connections in each state by each external system your application connects. If you notice particular state’s count start to grow i.e. CLOSE-WAIT or LAST-ACK … then it could be indication that some kind of network connectivity issue is brewing the application.
$ netstat -an | grep 'TIME_WAIT' | wc -l
Above command shows number of connections in ‘TIME_WAIT’ state. Similarly, you can grep for other states as well.
# 11. OPEN FILE DESCRIPTORS
File descriptor is a handle to access
(a). File
(b). Pipe (is a mechanism for inter-process communication using message passing. i.e. ls -l | grep key | less)
(c). Network Connections.
If you notice File descriptors counts to be growing in your application, it can be lead indicator that application isn’t closing resources properly. Unclosed file descriptors after it’s utilization will lead to performance/availability problems.
Below command will report all the open file descriptors for the process Id ‘5666’.
lsof -p 5666
If you want to know number of open file descriptors for the same process, you need to issue the command:
$ lsof -p 5666 | wc -l
153
Storage related micrometrics
There are 3 storage related micrometrics that you can focus on:
- IOPS
- Storage Throughput
- Storage Latency
Let’s discuss them in this section.
# 12. IOPS
IO operations per second, which means the amount of read or write operations that could be done in one second time. For certain IO operations, IO request size can be very small. Examples of IO size could be 4 KB, 8 KB, 32 KB and so on. So larger IO request sizes could mean less IOPS
13. STORAGE THROUGHPUT
Storage throughput is basically common value that shows how much a storage can deliver. This number is usually expressed in Megabytes / Second (MB/s), example 140 MB/s. Below formulae derives throughput.
Average IO size x IOPS = Throughput in MB/s
# 14. STORAGE LATENCY
Each IO request will take some time to complete, this is called the average latency. This latency is measured in milliseconds and should be as low as possible. There are several factors that would affect this time. Many of them are physical limits due to the mechanical constructs of the traditional hard disk.
Database related micrometrics
This article is intended to cover only micrometrics of the application layer. However, monitoring micrometics of database can also be fruitful. Here is the list of micrometrics that can be monitored on the DB:
# 15. DB – Locks
# 16. Long running queries
# 17. Evictions of in-memory tables
# 18. Hits/miss ratio
Conclusion
This micrometrics can be monitored in production environment for forecast brewing production problems. On top of it, they can be used in CI/CD pipeline to monitor code quality.
We hope you find this micrometrics to be useful. If you think there are more powerful micrometrics that can forecast application performance, you email us team@tier1app.com. We will be glad to update this article with the metrics you had pointed out.

Leave a comment